Some blogs almost write themselves. This hasn't been one of them.
It all started when I read a journal article - to which I'd now link if I could find the darned thing again - that suggested a bias in NFL (or maybe it was College Football) spread betting markets arising from bookmakers' tendency to over-correct when a team won on line betting. The authors found that after a team won on line betting one week it was less likely to win on line betting next week because it was forced to overcome too large a handicap.
Naturally, I wondered if this was also true of AFL spread betting.
What Makes a Team's Start Vary from Week-to-Week?
In the process of investigating that question, I wound up wondering about the process of setting handicaps in the first place and what causes a team's handicap to change from one week to the next.
Logically, I reckoned, the start that a team receives could be described by this equation:
Start received by Team A (playing Team B) = (Quality of Team B - Quality of Team A) - Home Status for Team A
In words, the start that a team gets is a function of its quality relative to its opponent's (measured in points) and whether or not it's playing at home. The stronger a team's opponent the larger will be the start, and there'll be a deduction if the team's playing at home. This formulation of start assumes that game venue only ever has a positive effect on one team and not an additional, negative effect on the other. It excludes the possibility that a side might be a P point worse side whenever it plays away from home.
With that as the equation for the start that a team receives, the change in that start from one week to the next can be written as:
Change in Start received by Team A = Change in Quality of Team A + Difference in Quality of Teams played in successive weeks + Change in Home Status for Team A
To use this equation for we need to come up with proxies for as many of the terms that we can. Firstly then, what might a bookie use to reassess the quality of a particular team? An obvious choice is the performance of that team in the previous week relative to the bookie's expectations - which is exactly what the handicap adjusted margin for the previous week measures.
Next, we could define the change in home status as follows:
- Change in home status = +1 if a team is playing at home this week and played away or at a neutral venue in the previous week
- Change in home status = -1 if a team is playing away or at a neutral venue this week and played at home in the previous week
- Change in home status = 0 otherwise
This formulation implies that there's no difference between playing away and playing at a neutral venue. Varying this assumption is something that I might explore in a future blog.
From Theory to Practicality: Fitting a Model
(well, actually there's a bit more theory too ...)
Having identified a way to quantify the change in a team's quality and the change in its home status we can now run a linear regression in which, for simplicity, I've further assumed that home ground advantage is the same for every team.
We get the following result using all home-and-away data for seasons 2006 to 2010:
For a team (designated to be) playing at home in the current week:
Change in start = -2.453 - 0.072 x HAM in Previous Week - 8.241 x Change in Home Status
For a team (designated to be) playing away in the current week:
Change in start = 3.035 - 0.155 x HAM in Previous Week - 8.241 x Change in Home Status
These equations explain about 15.7% of the variability in the change in start and all of the coefficients (except the intercept) are statistically significant at the 1% level or higher.
(You might notice that I've not included any variable to capture the change in opponent quality. Doubtless that variable would explain a significant proportion of the otherwise unexplained variability in change in start but it suffers from the incurable defect of being unmeasurable for previous and for future games. That renders it not especially useful for model fitting or for forecasting purposes.
Whilst that's a shame from the point of view of better modelling the change in teams' start from week-to-week, the good news is that leaving this variable out almost certainly doesn't distort the coefficients for the variables that we have included. Technically, the potential problem we have in leaving out a measure of the change in opponent quality is what's called an omitted variable bias, but such bias disappears if the the variables we have included are uncorrelated with the one we've omitted. I think we can make a reasonable case that the difference in the quality of successive opponents is unlikely to be correlated with a team's HAM in the previous week, and is also unlikely to be correlated with the change in a team's home status.)
Using these equations and historical home status and HAM data, we can calculate that the average (designated) home team receives 8 fewer points start than it did in the previous week, and the average (designated) away team receives 8 points more.
All of which Means Exactly What Now?
Okay, so what do these equations tell us?
Firstly let's consider teams playing at home in the current week. The nature of the AFL draw is such that it's more likely than not that a team playing at home in one week played away in the previous week in which case the Change in Home Status for that team will be +1 and their equation can be rewritten as
Change in Start = -10.694 - 0.072 x HAM in Previous Week
So, the start for a home team will tend to drop by about 10.7 points relative to the start it received in the previous week (because they're at home this week) plus about another 1 point for every 14.5 points lower their HAM was in the previous week. Remember: the more positive the HAM, the larger the margin by which the spread was covered.
Next, let's look at teams playing away in the current week. For them it's more likely than not that they played at home in the previous week in which case the Change in Home Status will be -1 for them and their equation can be rewritten as
Change in Start = 11.276 - 0.155 x HAM in Previous Week
Their start, therefore, will tend to increase by about 11.3 points relative to the previous week (because they're away this week) less 1 point for every 6.5 points lower their HAM was in the previous week.
Away teams, therefore, are penalised more heavily for larger HAMs than are home teams.
This I offer as one source of potential bias, similar to the bias that was found in the original article I read.
Proving the Bias
As a simple way of quantifying any bias I've fitted what's called a binary logit to estimate the following model:
Probability of Winning on Line Betting = f(Result on Line Betting in Previous Week, Start Received, Home Team Status)
This model will detect any bias in line betting results that's due to an over-reaction to the previous week's line betting results, a tendency for teams receiving particular sized starts to win or lose too often, or to a team's home team status.
The result is as follows:
logit(Probability of Winning on Line Betting) = -0.0269 + 0.054 x Previous Line Result + 0.001 x Start Received + 0.124 x Home Team Status
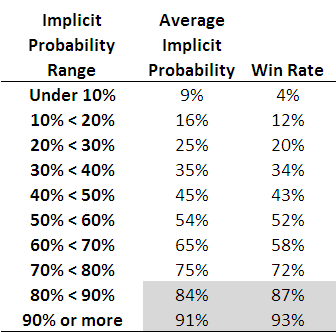
The only coefficient that's statistically significant in that equation is the one on Home Team Status and it's significant at the 5% level. This coefficient is positive, which implies that home teams win on line betting more often than they should.
Using this equation we can quantify how much more often. An away team, we find, has about a 46% probability of winning on line betting, a team playing at a neutral venue has about a 49% probability, and a team playing at home has about a 52% probability.
That is undoubtedly a bias, but I have two pieces of bad news about it. Firstly, it's not large enough to overcome the vig on line betting at $1.90 and secondly, it disappeared in 2010.
Do Margins Behave Like Starts?
We now know something about how the points start given by the TAB Sportsbet bookie responds to a team's change in estimated quality and to a change in a team's home status. Do the actual game margins respond similarly?
One way to find this out is to use exactly the same equation as we used above, replacing Change in Start with Change in Margin and defining the change in a team's margin as its margin of victory this week less its margin of victory last week (where victory margins are negative for losses).
If we do that and run the new regression model, we get the following:
For a team (designated to be) playing at home in the current week:
Change in Margin = 4.058 - 0.865 x HAM in Previous Week + 8.801 x Change in Home Status
For a team (designated to be) playing away in the current week:
Change in Margin = -4.571 - 0.865 x HAM in Previous Week + 8.801 x Change in Home Status
These equations explain an impressive 38.7% of the variability in the change in margin. We can simplify them, as we did for the regression equations for Change in Start, by using the fact that the draw tends to alternate team's home and away status from one week to the next.
So, for home teams:
Change in Margin = 12.859 - 0.865 x HAM in Previous Week
While, for away teams:
Change in Margin = -13.372 - 0.865 x HAM in Previous Week
At first blush it seems a little surprising that a team's HAM in the previous week is negatively correlated with its change in margin. Why should that be the case?
It's a phenomenon that we've discussed before: regression to the mean. What these equations are saying are that teams that perform better than expected in one week - where expectation is measured relative to the line betting handicap - are likely to win by slightly less than they did in the previous week or lose by slightly more.
What's particularly interesting is that home teams and away teams show mean regression to the same degree. The TAB Sportsbet bookie, however, hasn't always behaved as if this was the case.
Another Approach to the Source of the Bias
Bringing the Change in Start and Change in Margin equations together provides another window into the home team bias.
The simplified equations for Change in Start were:
Home Teams: Change in Start = -10.694 - 0.072 x HAM in Previous Week
Away Teams: Change in Start = 11.276 - 0.155 x HAM in Previous Week
So, for teams whose previous HAM was around zero (which is what the average HAM should be), the typical change in start will be around 11 points - a reduction for home teams, and an increase for away teams.
The simplified equations for Change in Margin were:
Home Teams: Change in Margin = 12.859 - 0.865 x HAM in Previous Week
Away Teams: Change in Margin = -13.372 - 0.865 x HAM in Previous Week
So, for teams whose previous HAM was around zero, the typical change in margin will be around 13 points - an increase for home teams, and a decrease for away teams.
Overall the 11-point v 13-point disparity favours home teams since they enjoy the larger margin increase relative to the smaller decrease in start, and it disfavours away teams since they suffer a larger margin decrease relative to the smaller increase in start.
To Conclude
Historically, home teams win on line betting more often than away teams. That means home teams tend to receive too much start and away teams too little.
I've offered two possible reasons for this:
- Away teams suffer larger reductions in their handicaps for a given previous weeks' HAM
- For teams with near-zero previous week HAMs, starts only adjust by about 11 points when a team's home status changes but margins change by about 13 points. This favours home teams because the increase in their expected margin exceeds the expected decrease in their start, and works against away teams for the opposite reason.
If you've made it this far, my sincere thanks. I reckon your brain's earned a spell; mine certainly has.