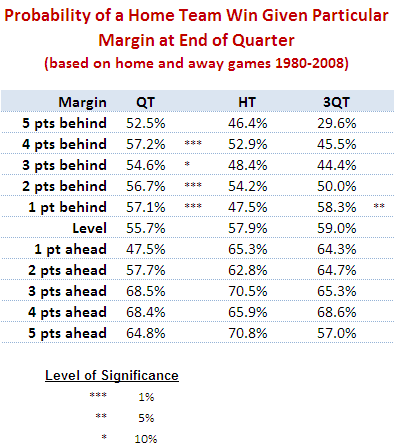
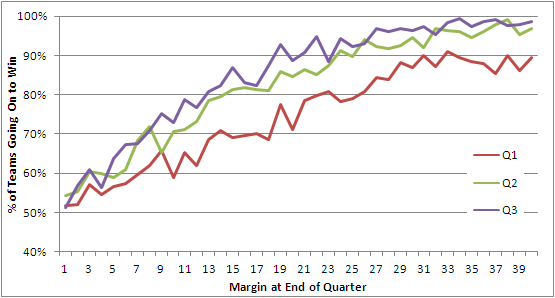
As so many traders discovered to their individual and often, regrettably, our collective cost over the past few years, betting against longshots, deliberately or implicitly, can be a very lucrative gig until an event you thought was a once-in-a-virtually-never affair crops up a couple of times in a week. And then a few more times again after that.
To put a footballing context on the topic, let's imagine that a friend puts the following proposition bet to you: if none of the first 100 home-and-away games next season includes one with a handicap-adjusted margin (HAM) for the home team of -150 or less he'll pay you $100; if there is one or more games with a HAM of -150 or less, however, you pay him $10,000.
For clarity, by "handicap-adjusted margin" I mean the number that you get if you subtract the away team's score from the home team's score and then add the home team's handicap. So, for example, if the home team was a 10.5 point favourite but lost 100-75, then the handicap adjusted margin would be 75-100-10.5, or -35.5 points.
A First Assessment
At first blush, does the bet seem fair?
We might start by relying on the availability heuristic and ask ourselves how often we can recall a game that might have produced a HAM of -150 or less. To make that a tad more tangible, how often can you recall a team losing by more than 150 points when it was roughly an equal favourite or by, say, 175 points when it was a 25-point underdog?
Almost never, I'd venture. So, offering 100/1 odds about this outcome occurring once or more in 100 games probably seems attractive.
Ahem ... the data?
Maybe you're a little more empirical than that and you'd like to know something about the history of HAMs. Well, since 2006, which is a period covering just under 1,000 games and that spans the entire extent - the whole hog, if you will - of my HAM data, there's never been a HAM under -150.
One game produced a -143.5 HAM; the next lowest after that was -113.5. Clearly then, the HAM of -143.5 was an outlier, and we'd need to see another couple of scoring shots on top of that effort in order to crack the -150 mark. That seems unlikely.
In short, we've never witnessed a HAM of -150 or less in about 1,000 games. On that basis, the bet's still looking good.
But didn't you once tell me that HAMs were Normal?
Before we commit ourselves to the bet, let's consider what else we know about HAMs.
Previously, I've claimed that HAMs seemed to follow a normal distribution and, in fact, the HAM data comfortably passes the Kolmogorov-Smirnov test of Normality (one of the few statistical tests I can think of that shares at least part of its name with the founder of a distillery).
Now technically the HAM data's passing this test means only that we can't reject the null hypothesis that it follows a Normal distribution, not that we can positively assert that it does. But given the ubiquity of the Normal distribution, that's enough prima facie evidence to proceed down this path of enquiry.
To do that we need to calculate a couple of summary statistics for the HAM data. Firstly, we need to calculate the mean, which is +2.32 points, and then we need to calculate the standard deviation, which is 36.97 points. A HAM of -150 therefore represents an event approximately 4.12 standard deviations from the mean.
If HAMs are Normal, that's certainly a once-in-a-very-long-time event. Specifically, it's an event we should expect to see only about every 52,788 games, which, to put it in some context, is almost exactly 300 times the length of the 2010 home-and-away season.
With a numerical estimate of the likelihood of seeing one such game we can proceed to calculate the likelihood of seeing one or more such game within the span of 100 games. The calculation is 1-(1-1/52,788)^100 or 0.19%, which is about 525/1 odds. At those odds you should expect to pay out that $10,000 about 1 time in 526, and collect that $100 on the 525 other occasions, which gives you an expected profit of $80.81 every time you take the bet.
That still looks like a good deal.
Does my tail look fat in this?
This latest estimate carries all the trappings of statistically soundness, but it does hinge on the faith we're putting in that 1 in 52,788 estimate, which, in turn hinges on our faith that HAMs are Normal. In the current instance this faith needs to hold not just in the range of HAMs that we see for most games - somewhere in the -30 to +30 range - but way out in the arctic regions of the distribution rarely seen by man, the part of the distribution that is technically called the 'tails'.
There are a variety of phenomena that can be perfectly adequately modelled by a Normal distribution for most of their range - financial returns are a good example - but that exhibit what are called 'fat tails', which means that extreme values occur more often than we would expect if the phenomenon faithfully followed a Normal distribution across its entire range of potential values. For most purposes 'fat tails' are statistically vestigial in their effect - they're an irrelevance. But when you're worried about extreme events, as we are in our proposition bet, they matter a great deal.
A class of distributions that don't get a lot of press - probably because the branding committee that named them clearly had no idea - but that are ideal for modelling data that might have fat tails are the Stable Distributions. They include the Normal Distribution as a special case - Normal by name, but abnormal within its family.
If we fit (using Maximum Likelihood Estimation if you're curious) a Stable Distribution to the HAM data we find that the best fit corresponds to a distribution that's almost Normal, but isn't quite. The apparently small difference in the distributional assumption - so small that I abandoned any hope of illustrating the difference with a chart - makes a huge difference in our estimate of the probability of losing the bet. Using the best fitted Stable Distribution, we'd now expect to see a HAM of -150 or lower about 1 game in every 1,578 which makes the likelihood of paying out that $10,000 about 7%.
Suddenly, our seemingly attractive wager has a -$607 expectation.
Since we almost saw - if that makes any sense - a HAM of -150 in our sample of under 1,000 games, there's some intuitive appeal in an estimate that's only a bit smaller than 1 in 1,000 and not a lot smaller, which we obtained when we used the Normal approximation.
Is there any practically robust way to decide whether HAMs truly follow a Normal distribution or a Stable Distribution? Given the sample that we have, not in the part of the distribution that matters to us in this instance: the tails. We'd need a sample many times larger than the one we have in order to estimate the true probability to an acceptably high level of certainty, and by then would we still trust what we'd learned from games that were decades, possibly centuries old?
Is There a Lesson in There Somewhere?
The issue here, and what inspired me to write this blog, is the oft-neglected truism - an observation that I've read and heard Nassim Taleb of "Black Swan" fame make on a number of occasions - that rare events are, well, rare, and so estimating their likelihood is inherently difficult and, if you've a significant interest in the outcome, financially or otherwise dangerous.
For many very rare events we simply don't have sufficiently large or lengthy datasets on which to base robust probability estimates for those events. Even where we do have large datasets we still need to justify a belief that the past can serve as a reasonable indicator of the future.
What if, for example, the Gold Coast team prove to be particularly awful next year and get thumped regularly and mercilessly by teams of the Cats' and the Pies' pedigrees? How good would you feel than about betting against a -150 HAM?
So when some group or other tells you that a potential catastrophe is a 1-in-100,000 year event, ask them what empirical basis they have for claiming this. And don't bet too much on the fact that they're right.