In recent blogs about the Very Simple Ratings System (VSRS) I've been using as my Probability Score metric the Brier Score, which assigns scores to probability estimates on the following basis:
Brier Score = (Actual Result - Probability Assigned to Actual Result)^2
For the purposes of calculating this score the Actual Result is treated as (0,1) variable, taking on a value of 1 if the team in question wins, and a value of zero if that team, instead, loses. Lower values of the Brier Score, which can be achieved by attaching large probabilities to teams that win or, equivalently, small probabilities to teams that lose, reflect better probability estimates.
Elsewhere in MAFL I've most commonly used, rather than the Brier Score, a variant of the Log Probability Score (LPS) in which a probability assessment is scored using the following equation:
Log Probability Score = 1 + logbase2(Probability Associated with Winning team)
In contrast with the Brier Score, higher log probabilities are associated with better probability estimates.
Both the Brier Score and the Log Probability Score metrics are what are called Proper Scoring Rules, and my preference for the LPS has been largely a matter of taste rather than of empirical evidence of superior efficacy.
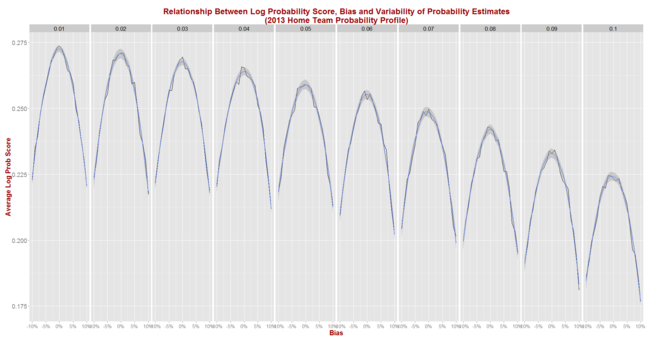
Because the LPS has been MAFL's probability score of choice for so long, however, I have previously written a blog about empirically assessing the relative merits of a predictor's season-average LPS result in the context of the profile of pre-game probabilities that prevailed in the season under review. Such context is important because the average LPS that a well-calibrated predictor can be expected to achieve depends on the proportion of evenly-matched and highly-mismatched games in that season. (For the maths on this please refer to that earlier blog.)
WHAT'S A GOOD BRIER SCORE?
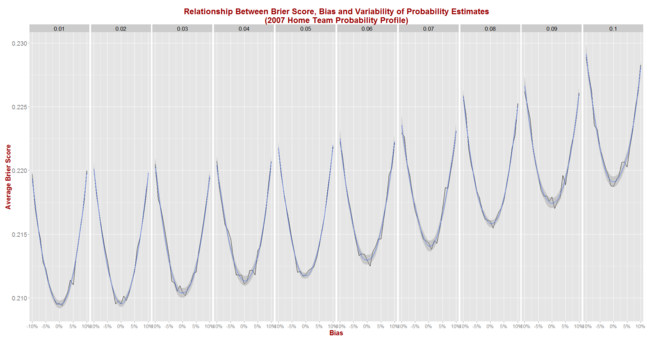
What I've not done previously is provide similar, normative data about the Brier Score. That's what this blog will address.
Adopting a methodology similar to that used in the earlier blog establishing the LPS norms, for this blog I've:
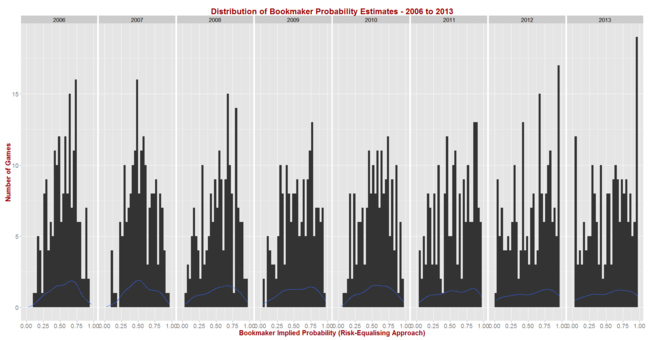
- Calculated the implicit bookmaker probabilities (using the Risk-Equalising approach) for all games in the 2006 to 2013 period
- Assumed that the predictor to be simulated assigns probabilities to games as if making a random selection from a Normal distribution with mean equal to the true probability - as assessed in the step above - plus some bias between -10% and +10% points, and with some standard deviation (sigma) in the range 1% to 10% points. Probability assessments that fall outside the (0.01, 0.99) range are clipped. Better tipsters are those with smaller (in absolute terms) bias and smaller sigma.
- For each of the simulated (bias, sigma) pairs, simulated 1,000 seasons with the true probabilities for every game drawn from the empirical implicit bookmaker probabilities for a specific season.
Before I reveal the results for the first set of simulations let me first report on the season-by-season profile of implicit bookmaker probabilities, based on my TAB Sportsbet data.